This one PR trick
Hey y'all!
I have an important PR:
> ...
> 131 files changed, 1255 insertions(+), 318 deletions(-)
Anyone up for a review?

Huge PRs can be a scary thing. When PRs like this are in review queue one I've seen following happen:
- PR is pushed away for as long as possible (or even to oblivion)
- Reviewer studies PR for a long time and their energy is drained to last drop
- PR is skimmed top to bottom and pushed forward with "not my problem" attitude
Everyone knows that such huge pull requests should be split into smaller, reviewable ones. And yet they still happen from time to time.
Not all code is modular and replaceable in phases. Change might be very binary. Either working completely or not at all. In scenarios where either feature or change is highly interconnected one file.
Allow me to provide concrete example - JavaScript dependency upgrade. Something that can result in a hellish update cycle (none of the change can be made separately)
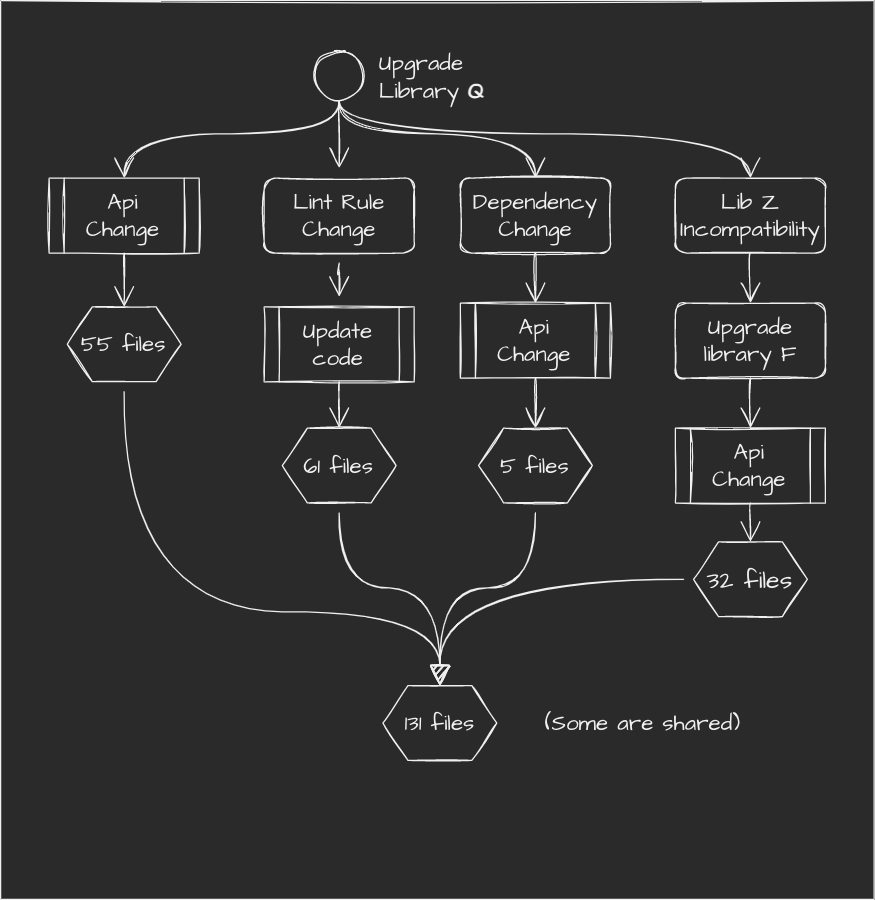
Huge? Yeah, but that's OK. Someone else took their time and finished it. PR is hanging, we only need to review it. Single commit:
commit 3b18e512dba79e4c8300dd08aeb37f8e728b8dad
Author: John Dev. Man <[email protected]>
Date: Wed Nov 28 22:42:45 2055 +0100
Upgrade Library Q to version 3.19
Also:
- Change formatting due to lint error (enforced by new Q's ruleset)
- Change of usage of R0 ([email protected] requires different call)
- Upgrade of library F (Z's dependency, but F and new Q don't work)
- Chance Z's calls due to update of F (and also some F params)
(...)
131 file changed, 1255 insertions(+), 318 deletions(-)

FUN. Right?! And by the way - I'm guilty of that too.
There's an easy fix though.
I'm going to use of behind-the-scenes magic and split this big, bulky PR into logical pieces. Previously single commit PR is transformed into this:
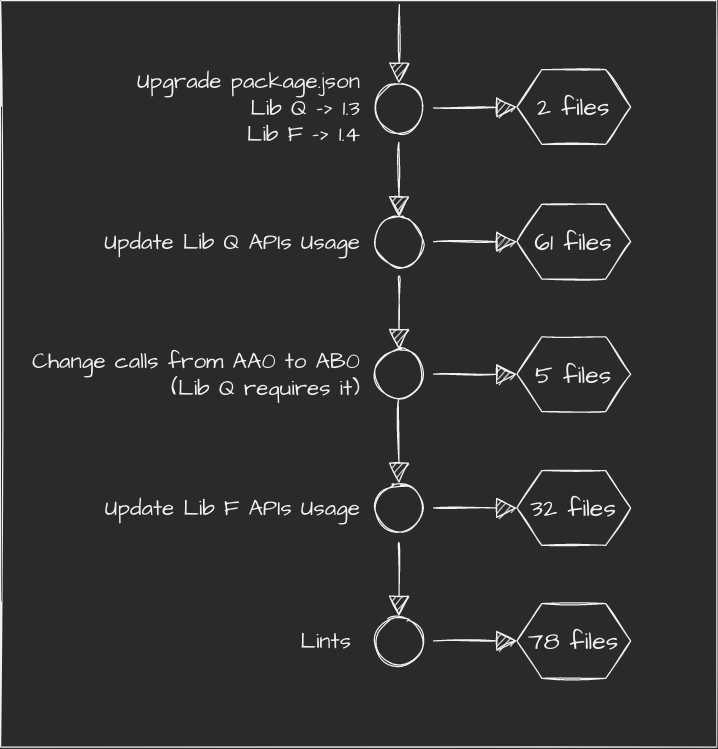
Let's walk through the new structure commit by commit:
- First commit modified 2 files - package.json and a lockfile.Reviewer verifies if the there is no scope spillage (i.e. more updates than expected).
- Second commit modified 61 files. It includes API changes related to the "core" purpose. It's big and meaty, but there should be visible patterns. After all - no new logic is written.
- Similar to 2nd commit - only 5 files. Since the pattern is different, they're moved away to not distract reviewer.
- Another big API change and another unique pattern of change. 32 files set isn't trivial but once again there's expectation that easily distinguishable pattern exists.
- Lints - 78 files. Often can be skimmed. It's easy to distinguish lint-only changes.Lints can be misleading (in JS at least), but we hope we have a human behind the review.
In the end we have exactly the same number of files changed. Diff would be the same, but they're grouped and can be reviewed one after another. We, as a humans are quite capable in spotting patterns, so with assumption that change patterns repeat the number of "change" to review is much more manageable.
Of course we can go even further. For example we can split 2nd commit for Lib Q into two, so that one have exactly the same patter all around the commit and changes that don't fit the pattern are extracted to another piece.
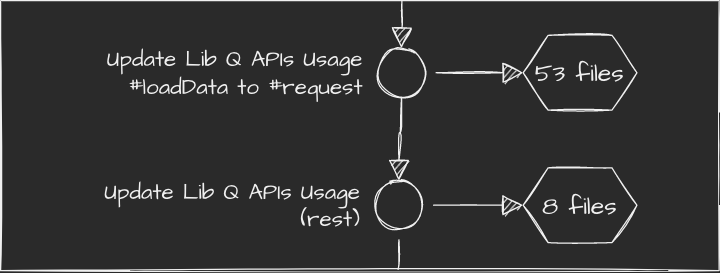
Conceptually first part of the split is the same change repeated 53 times. Neat!
Of course such setup isn't obtainable a priori when working on a change.
I wouldn't expect anyone to be able of carefully plan their work to such degree (but if you can, kudos to you!).
Transformations should be done with Git (or other SCM) after all the changes were done and are ready for review. If there is extensive feedback one could once again clean it up and either force-push or create new PR in place. Newcomers won't have to review 10 original commits and 20 feedback implementation ones.
When it comes to Git I wouldn't describe its CLI as the most intuitive software. Even after many years I still don't have advanced usage imprinted on my brain and need to search in documentation often. Thankfully, nowadays there are many tools that can help in doing advanced tasks without losing all hairs in the process.
Some of them, that I saw and can recommend are:
- Magit for Emacs (my personal favorite, Emacs dependency might be too much for some) - Linux, Mac, Windows - Open Source
- Fork - very fast and feature rich Git GUI - very fast - Mac and Windows - ~40$
- Sublime Merge - feature rich with some interesting features (like showing raw Git calls) - Linux, Mac, Windows - ~90$
Before you dive in - there are some gotchas I feel I need to highlight.
End result is not always sum of its products. While different parts of changeset can feel "OK", the full change might not produce expected result. For example some JavaScript related lints might require specific Babel (JS transpiler) setup - so while they look innocent they can cause problems in the long run.
Consistency might also be a trap. It might give false sense of security and yet be completely incorrect.
Another obvious thing is that even nicely organized changeset still won't show omissions (neither will single-commit though).
Changing API usage in 98 of 100 cases will look good on diff but maybe reviewer should search code base to ensure no other calls remain.
In the end I'd recommend using this technique to group changes by logical units. It's not a silver bullet but it can make reviewing easier. Not all changes are linear and some pull additional requirements.
Ideally PRs should be light and designed for a reviews in a same way like code should be designed to be testable by unit tests. But when that's impossible and pushed out change is a big ball of mud it's a handy technique to know.